Crawl là gì? Crawl là một quá trình thu thập thông tin từ các trang web hoặc các nguồn dữ liệu trực tuyến khác. Với SEOer, crawl đặc biệt có ý nghĩa, bởi nó sẽ tìm kiếm và trích xuất những dữ liệu cần thiết theo một cấu trúc nhất định trên trang web để đề xuất cho người duyệt web.
Crawl data và những điều bạn chưa biết
Crawl còn được gọi là là thu thập dữ liệu hoặc web scraping, thường được thực hiện bởi các phần mềm đặc biệt gọi là bot hoặc spider. Crawl sẽ thu thập đồng thời thông tin ở các định dạng như web, hình ảnh, video, file PDF,...
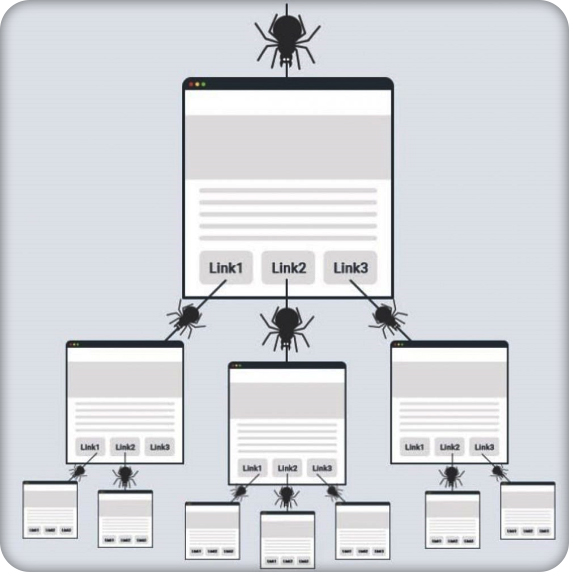
Quá trình Crawl sẽ tạo thành một mạng lưới thông tin rộng lớn, khởi nguồn từ một URL của trang web với các liên kết trên đó. Các con bot sẽ thực hiện nhiệm vụ thu thập các nguồn dữ liệu kết nối này, tiếp tục nhân rộng ra cho đến khi các trang liên quan được Crawl hết dữ liệu. Các thông tin sau quá trình thu thập sẽ được lưu trữ trong một cơ sở dữ liệu để các công cụ tìm kiếm hoặc ứng dụng sử dụng về sau.

Mỗi công cụ tìm kiếm đều có một chương trình Crawl nhất định với các bot được lập trình sẵn. Chúng tiến hành thu gom thông tin theo chỉ dẫn cụ thể, lập chỉ mục chọn lọc. Nhờ vậy, các công cụ tìm kiếm sẽ cung cấp dữ liệu đáp ứng truy vấn tìm kiếm của người dùng chính xác hơn, phù hợp hơn. Nếu bạn quan sát, mỗi khi bạn search chủ đề nào đó trên Google, kết quả sẽ hiển thị danh sách các đường link địa chỉ liên quan đến chủ đề tìm kiếm. Quá trình Crawl data đã thực hiện rà soát, đánh giá và liên kết các đường link trên website, đáp ứng các nhu cầu tìm kiếm từ người dùng.
Quy trình Crawl dữ liệu diễn ra như thế nào?
Quy trình Crawl dữ liệu hay cách thức bot thu thập thông tin được diễn ra như sau:
- Bản đồ trang web (sitemap) sẽ cung cấp cho các bot một danh sách các trang trên một website nhất định (các backlink đang có trên website).
- Các bot trình duyệt sẽ bắt đầu từ một trang web đã biết, chúng rà soát và theo dõi các liên kết đến các trang khác.
- Bot có thể được lập trình để tìm kiếm các trang web dựa trên các từ khóa hoặc chủ đề nhất định. Quá trình tìm các web liên quan, web crawl sẽ xác định độ ưu tiên cửa từng trang web dựa trên các yếu tố về độ quan trọng, độ tin cậy, tính phổ biến hay thời gian cập nhật.
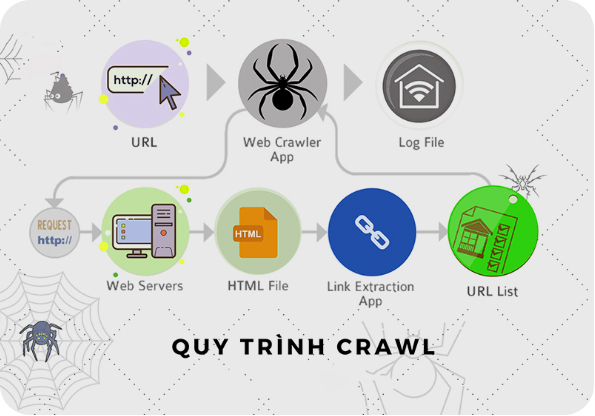
- Sau khi thu thập hết liên kết trên website, bot gửi một yêu cầu đến máy chủ web và máy chủ web trả về mã nguồn HTML của trang. Lưu ý, trước đó web crawler sẽ tiến hành đánh giá về độ sâu website, tức là số lượng liên kết cần theo dõi để thu thập thông tin từ trang đó.
- Bot tiến hành phân tích mã nguồn HTML để tìm kiếm, xác định các phần tử chứa dữ liệu cần thiết về tiêu đề, nội dung văn bản, hình ảnh, backlink,...
- Tiếp đến bot trích xuất dữ liệu từ các phần tử đã tìm thấy và lưu trữ chúng vào một định dạng nhất định. Tập dữ liệu này sẽ được cất giữ trong một cơ sở dữ liệu.
- Quá trình thu thập dữ liệu sẽ tiếp tục từ trang này đến trang liên kết khác cho đến khi đạt được điều kiện dừng nhất định. Điều kiện này có thể là hạn mức thời gian, hạn mức lượng thông tin.
Tại sao lại cần crawl dữ liệu?
Internet là một thế giới rộng lớn với lượng thông tin khổng lồ và ngày càng gia tăng. Nếu không có crawl web quá trình thu thập, xử lý dữ liệu không thể diễn ra, tất yếu người duyệt web sẽ nhìn thấy các luồng thông tin rời rạc, những nội dung thiếu tính liên kết.

Crawl dữ liệu mang đến những giá trị như sau:
- Crawl thu thập lượng thông tin khổng lồ trong thời gian ngắn mà con người không thể làm được.
- Bot thu thập dữ liệu của các công cụ tìm kiếm (điển hình như Google) được lập trình để tự động cập nhật dữ liệu mới từ website, các nguồn dữ liệu trực tuyến khác.
- Dữ liệu sau khi thu thập sẽ được phân tích để đánh giá xu hướng, xác định hình mẫu để đưa ra các gợi ý nội dung cho người tìm kiếm.
- Đối với website, crawl data sẽ thu thập hết các liên kết trên trang của bạn, giúp công cụ tìm kiếm hiểu về nội dung bạn khai báo để quá trình lập chỉ mục trang diễn ra hiệu quả, để đánh giá nội dung có phù hợp với truy vấn người dùng không và đưa ra quyết định xếp hạng website.
Các công cụ Crawl phổ biến hiện nay phải kể đến Googlebot của Google, Bingbot của Bing, Yandexbot của Yandex.
Những lỗi phổ biến trên website khiến Crawl dữ liệu không hiệu quả
Rất nhiều trường hợp website có quá trình crawl kém, dẫn đến công cụ tìm kiếm không đánh giá cao, không ghi nhận được dữ liệu .Tất yếu trang của chúng ta sẽ rất khó để thu thập thông tin, việc out top là điều khó tránh.
Nếu website điều hướng trên thiết bị di động khác với trên máy tính, trang web có cấu trúc phức tạp, sử dụng nhiều JavaScript sẽ gây khó khăn cho crawl dữ liệu. Khi code web bị lỗi hoặc chủ web thay đổi nội dung thường xuyên sẽ làm hạn chế khả năng thu thập dữ liệu của bot. Một số vấn đề khác về quyền như tính bảo mật, tệp robot.txt của website chặn bot truy cập, bản quyền trang,... cũng có thể ảnh hưởng đến hiệu quả crawl data.
Giải pháp:
Khi thiết kế website bất động sản bạn phải tạo sitemap sau đó khai báo sitemap trong google search console giúp Bot crawl data website một cách dễ dàng. Cấu trúc website được thiết kế đơn giản rành mạch, đồng bộ trên máy tính và điện thoại.
Bạn cần đi link nội bộ giữa các bài viết trên website giúp google khám phá website của bạn dễ hàng hơn.
Trên đây là các thông tin về Crawl dữ liệu, Bdsweb hy vọng bài viết đã giúp bạn có thêm những kiến thức hữu ích về website.
- Entity là gì? Cách SEO entity hiệu quả nhất
- Các cách SEO hình ảnh lên Google hiệu quả nhất
- Cách thống kê lượng truy cập website: Tầm quan trọng và cách thực hiện tốt nhất
- geotag images là gì? Cách gắn Geotag ảnh chuẩn SEO
- Bounce rate là gì? Bounce rate có quan trọng với SEO không?
- ALT text là gì? Tìm hiểu cách đặt ALT text chuẩn SEO